

撰文 | 张 宇
编辑 | 杨博丞
题图 | 图虫创意
1月16日,AI知识智能技术开发商智谱AI举办了首届技术开放日(Zhipu DevDay),全面展示了其投身大模型事业三年多以来所积累的技术成果,并发布了新一代基座大模型GLM-4。
智谱AI CEO张鹏表示,GLM-4的整体性能相比上一代大幅提升,逼近GPT-4,可以支持更长的上下文,具备更强的多模态能力。同时,GLM-4的推理速度更快,支持更高的并发,大大降低推理成本。

图源:智谱AI
除此之外,GLM-4大幅提升了智能体能力,GLM-4 All Tools实现自主根据用户意图,自动理解、规划复杂指令,自由调用网页浏览器、Code Interpreter代码解释器和多模态文生图大模型以完成复杂任务。GLMs个性化智能体定制功能亦同时上线,用户用简单的提示词指令就能创建属于自己的GLM智能体,大幅降低了大模型使用门槛。
“追赶OpenAI”“对标Open AI是智谱AI成立以来的目标”,是张鹏在对外分享时屡次提及的几句话,目前大模型的竞争已经不再是从0到1的有与无之争,而是落地之争,各家大模型开始贴身肉搏,被称为“中国OpenAI”的智谱AI,究竟能否在大模型角逐战中顺利突围?
一、暂时难以对标OpenAI
智谱AI作为国内第一开源大模型,有着较强的技术架构,但对标OpenAI仍有一些距离。
张鹏坦言,和国外大模型相比,国内的大模型发展起步晚了一些,加上高性能算力限制、数据质量的差距等,国内大模型在规模和核心能力上都与世界先进水平存在一定差距,这样的差距大约在一年左右。
从技术路线来看,OpenAI则更加注重通用性、可移植性和可扩展性,其GPT系列模型可以在多个场景下应用,并且具有高度的可定制性。相比之下,智谱AI的技术路线是“大模型+小模型”,通过大模型的预训练和微调,来适应不同场景和任务的需求。这种技术路线可以提高模型的泛化能力和应用范围,但也存在着模型复杂度高、计算量大、训练时间长等问题。
在模型规模,OpenAI的GPT系列模型规模较大,可以处理大量的自然语言数据,从而获得更好的模型性能。相比之下,智谱AI的模型规模可能较小,处理数据的能力有限,这可能会影响其模型性能和泛化能力。而在数据资源方面,OpenAI拥有大量的自然语言数据资源,可以用来训练和优化其模型。相比之下,智谱AI的数据资源可能相对较少,导致其模型训练的效果和性能受到限制。
这意味着,想要尽快弥补与OpenAI之间的差距,智谱AI必须要持续提升大模型能力,训练参数自然也需要提升,但硬币的另一面是,智谱AI在资金方面也将面临着一个巨大的难题。
首先,硬件是一笔巨额投入,根据美国市场研究机构TrendForce推算,处理ChatGPT的训练数据需要2万枚GPU芯片,而随着OpenAI进一步展开ChatGPT和其他GPT模型的商业应用,其GPU需求量将突破3万张(该报告计算以A100芯片为主)。
此外,训练大模型的成本也不容小觑,根据国盛证券发布的《ChatGPT需要多少算力》估算,GPT-3训练一次的成本约为140万美元,对于一些更大的LLM(大型语言模型),训练成本介于200万美元至1200万美元之间。
巨额资金从哪里来,以及能换回多少价值,对于智谱AI而言是一个未知数。
不过,好在智谱AI备受投资机构青睐。2023年10月,智谱AI称年内已成功融资超过25亿人民币。这一重要的融资里程碑得到了多家知名机构的积极支持,主要参与方包括社保基金、中关村自主创新基金、以及美团、蚂蚁、阿里、腾讯、小米、金山、顺为资本、Boss直聘、好未来、红杉、高瓴等多家机构,同时也包括一些老股东的跟投。
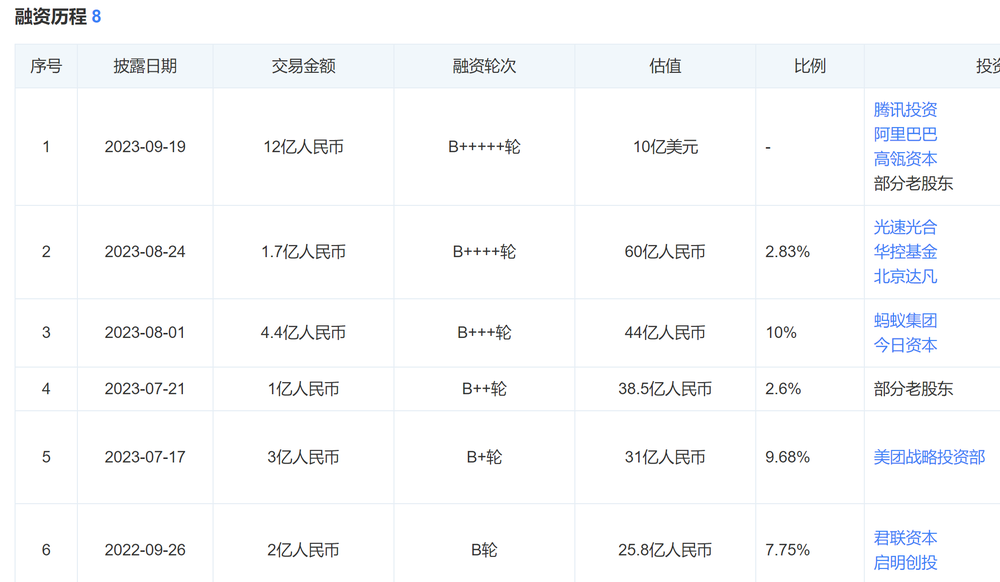
图源:天眼查
尤其是2023年至今,智谱AI接连拿下5轮融资,估值超过100亿元,跻身国内AI领域“独角兽”企业。智谱AI表示,融资将被用于进一步推动其基座大模型的研发,以更好地支持广泛的行业生态,促进与合作伙伴一起实现高速增长的愿景。
二、商业化高墙难越
商业化落地是验证一项新技术价值的最直接的方式。现阶段来看,国内大模型百花齐放,但大部分仍处于讲技术、讲发展的阶段,对于商业化落地,基本上处于探索阶段。
整体而言,大模型企业的盈利方式主要包括大模型、大模型+算力、大模型+应用。其中,大模型和大模型+算力为主要盈利方式。
智谱AI盈利方式和行业盈利方式基本一致,一是根据客户需求,提供大模型定制化开发服务,云端私有化本地私有化最高价格分别为120万元/年和3690万元/年;二是标准版大模型,提供API接入方式,按照Tokens使用收费,ChatGLM-Turbo、CharacterGLM、Text-Embedding收费标准分别为0.005元/千Tokens、0.015元/千Tokens、0.005元/千Tokens。目前,智谱AI的商业化主要面向企业和机构的B端用户。
作为对比,OpenAI的商业化同样分为C端和B端两个部分,具体而言,针对C端市场,OpenAI推出ChatGPT Plus订阅计划,每月收费20美元,相较于免费版本,即便在高峰时段用户也能正常访问ChatGPT,响应时间更快,并且可以优先使用新功能等。而针对B端市场,OpenAI发布了ChatGPT API,开发者可以将ChatGPT集成到产品中,以更加高效地发挥出价值。
值得注意的是,OpenAI还在2023年8月推出了企业服务版,该服务版有望每月给OpenAI带来6500万元的收入。整个2023年,OpenAI推出的多项付费方案已经带来了超过110亿元的收入。
一个普遍的现象在于,包括智谱AI在内的国内大模型产品,在高投入的同时还难以带来稳定的盈利。虽然大模型商业化之路道阻且长,但曙光已现。三六零2023年半年报显示,“360智脑”大模型已经开始创收,金额近2000万元;商汤集团也公布,生成式AI在2023年上半年相关收入增长670%。
爱分析相关报告指出,目前大模型商业化提速较快的行业为能源和金融,其原因在于这两个行业密集分布的央国企。央国企数据基础设施建设完备、算力投入高、AI应用场景多且基础强,这些原因促进央国企与大模型的快速融合。
对于智谱AI而言,目前大模型商业化的路径已经较为清晰,但能否走通大模型的商业化之路,关键不仅在于商业模式的探索尝试,更在于解决大模型发展的底层问题。
三、国产大模型何去何从?
根据工信部赛迪研究院最新数据,2023年我国语言大模型市场规模实现较快提升,应用场景不断丰富。预计2023年我国大模型市场规模将达到132.3亿元,增长率将达110%。
未来,随着技术的不断迭代进步,大模型将在具身智能、自动驾驶等领域开拓新的应用场景。
具体而言,大模型的发展将有三大趋势:首先是大模型智能能力的提升,未来大模型将具有更高的精度、更强的理解能力和更广泛的适用性,这意味着大模型能够更好地理解自然语言,还能够进行更多的复杂任务,比如全域控制、创作等等;其次是大模型将应用于更多领域,除了传统的文本处理之外,大模型也将在语音识别、图像生成、视频理解等方面发挥更大的作用,用户可以在更多的场景中享受到AI带来的便利。此外,大模型将更加定制化,能够更好地满足用户的个性化需求,用户可以根据自己的实际需求选择合适的模型,并进行定制化配置。
大模型飞速发展,但并不意味着无序发展。未来,针对大模型的监管将愈加严格,2023年7月,网信办等七部门发布了《生成式人工智能服务暂行管理办法》,明确规定大模型产品需注重数据隐私安全,不能非法获取、披露、利用个人信息和隐私、商业秘密,不可侵犯知识产权;大模型生成的内容应当体现社会主义核心价值观,不能生成歧视性的内容等等。
对于大模型的未来,张鹏显得十分乐观,“2024年,大模型市场将从野蛮生长回归冷静,对于大模型的投资与炒作将会告一段落,行业焦点也将从模型本身转向寻找应用。不过这并不代表大模型的技术演进速度会下降,向上探索的天花板还远远没到。”




